
In today’s rapidly changing technology landscape, machine learning and AI enable us to redefine industries and change how we interact with the world. AI allows developers to create more intelligent, flexible, and efficient applications. Arm, due to its unique position in the industry, has been enabling AI across a variety of platforms for more than a decade.
In this article, I want to detail how Arm’s technology allows developers to focus on innovation and the unique aspects of the applications they are developing while utilizing Arm’s existing technology.
You don’t need an NPU for AI applications
For over seven years, I’ve been making content about the advantages and disadvantages of different machine learning accelerators — called NPUs. These processors have their place in devices, but one myth is that you need one to run machine learning or AI tasks. That’s simply not true. AI tasks don’t hinge exclusively on NPUs; they can run on anything from a CPU to a GPU. With the technology found in Arm v8 and Arm v9 chips, you can run accelerated machine learning tasks particularly well on Arm CPUs.
Matrix multiplication is the key mathematical operation at the heart of machine learning and AI. GPUs and NPUs are good at matrix multiplication. However, modern Arm CPUs are also good at this processing task and have hardware accelerators that enable it, too. Whether it’s Arm v8 or Arm v9, Cortex-A or Cortex-X, or Arm’s Neoverse processors, they all have different technologies that allow the acceleration of matrix multiplication operations.
For example, Arm’s Neon technology, and Scalable Vector Extensions (SVE) are both available in Arm processors, there are also 8-bit matrix-by-matrix multiplication instructions in the Arm instruction set. In smartphones and on the edge devices, Scalable Matrix Extensions (SME) are available inside Arm processors. These technologies allow the CPU to perform accelerated matrix operations without a GPU or NPU.
Arm’s Kleidi technology
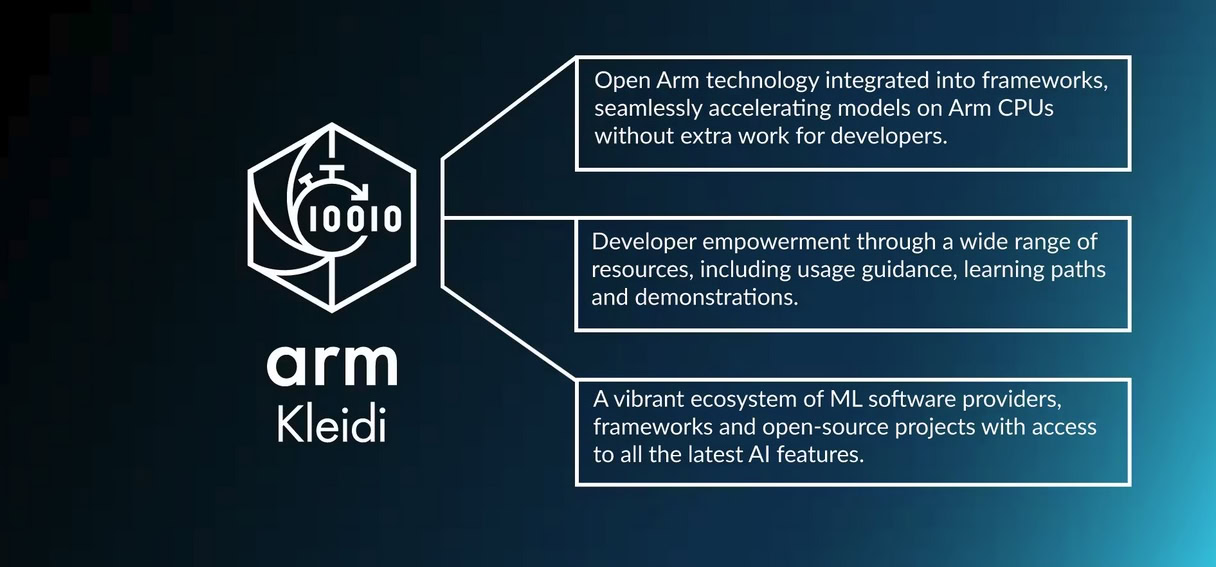
Beyond the hardware systems, Kleidi is a central part of Arm’s strategy for enabling AI on Arm-based mobile and server platforms. It covers a range of resources and partnerships for helping developers accelerate AI seamlessly on Arm, including a library of high-performance machine learning kernels called KleidiAI, which has been optimized for Arm CPUs using those various hardware accelerators.Kleidi is available on GitLab, and these kernels have been integrated into various frameworks that are ready for developers to use. As a result, we now have hardware acceleration for Arm CPUs, supporting various machine learning technologies, from classical machine learning to current generative AI.
Arm has integrated Kleidi technology into popular AI frameworks such as PyTorch and ExecuTorch, resulting in significant out-of-the-box performance improvements for developers. This integration ensures that developers can seamlessly leverage Arm’s optimized libraries within their existing workflows, gaining up to a 12x performance improvement with minimal effort.
Arm partnered with Meta to ensure the recently launched Llama 3.2 model works perfectly on Arm CPUs. The availability of smaller LLMs that enable fundamental text-based generative AI workloads, such as the one billion and three billion parameter versions, is critical for enabling AI inference at scale. Arm CPUs can run larger models, such as Llama 3.2 with 11 billion parameters and even the 90 billion parameter model in the cloud. These larger models are an excellent fit for CPU-based inference workloads in the cloud that generate text and images.
The 11 billion parameter version of Llama 3.2, running on an Amazon AWS Graviton4 processor, can achieve 29.3 tokens per second during the generation phase, and that’s just on the CPU. Thanks to the collaboration between Arm and Meta on the ExecuTorch framework, you can now access optimal performance by running those models on the edge. Running the new Llama 3.2 three billion LLM on an Arm-powered smartphone through the Arm CPU optimizations leads to a 5x improvement in prompt processing and a 3x improvement in token generation, achieving 19.92 tokens per second during the generation phase.
If you want a demonstration of this, check out my video above.
A massive boost for developers

Thanks to these advancements, the possibilities for developers are enormous. Think of everything you could do with a large language model running on a phone using an Arm CPU — no GPU, no NPU, no cloud, just the CPU. Arm’s approach is performance portability, which means that AI developers can optimize once and then deploy their models across various platforms without making any modifications. This is particularly useful for developers who need to deploy models both on the edge, in a smartphone, and in the cloud. By using Arm, developers can be sure that their model will also perform well on other platforms once optimized for one platform.
Arm has some great resources for developers, including documentation on how to accelerate generative AI and ML workloads when you choose to run them on Arm CPUs, in addition to running AI and ML on Android devices.
You might like
source https://www.androidauthority.com/how-arm-accelerates-ai-3504940/
0 Comments
Post a Comment